系统简介:
大数据体量巨大,数据类型繁多,价值密度低,要求处理速度快,业界将其归纳为4个“V”——Volume,Variety,Value,Velocity。因此,大数据过滤需要快速高效地过滤出有价值的知识与情报,需要达到的性能要求包括:海量处理规模、多字段过滤、智能筛选、高效过滤。灵玖IFCA系统是灵玖中科软件(北京)有限公司自主研发的大数据信息智能过滤与内容审计系统,可以快速便捷地匹配大量自定义的关键字、词,智能过滤违法国家法律法规以及侵犯用户权益的内容,达到净化网络空间、提取情报的目的,确保国家、社会与个人的信息内容安全。
IFCA系统充分融合了灵玖软件在自然语言理解、信息检索等方面多年的技术积累,具有智能、高效、自学习三大特点:
智能主要体现在专家启发式知识与机器学习的有机融合;
高效体现在本系统在保证准确率的情况下,可以单机每秒处理10MB的文本数据;
自学习是指通过机器学习,自动抽取新的语言知识,以适应新的网络语言变化,做到因时而变。
IFCA系统可应用于公安、广播、电视、报刊杂志以及广泛的网络信息内容安全服务。并可在IFCA基础上,提供进一步的数据信息监控等解决方案。
主要功能:
文本关键字、词智能高速匹配:
输入关键字、词,自动匹配,计算出该有关该字词的相关信息;用户定义的关键词数目不限,可以并发支持百万级别的关键词;
丰富的智能逻辑关系运输:
支持关键字、词复杂匹配,包括常用的“与、或、非”,同时支持“NEAR“临近关系的复杂算法;
按照用户自定义的类别体系分类整理过滤出的信息内容:
用户可以根据自身业务的特点,自定义内容过滤体系,IFCA系统将按照用户自定义的类别输出;
样本机器学习:
在没有关键词的时候,机器通过自动学习技能,同样能够达到对信息文本的相似类划分。
应用案例:
灵玖IFCA系统已经广泛的运用于各大公司和机构。
下面是IFCA为国家广电总局进行负面信息过滤的部分案例。
案例一:A片的信息过滤
下图分别给出了简单关键词匹配方法与IFCA智能过滤方法的对比结果图:
A片:
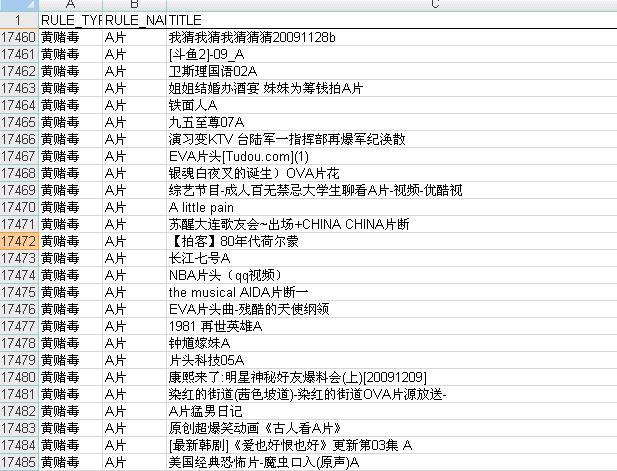
图1:简单关键词匹配方法的结果准确率不到10%
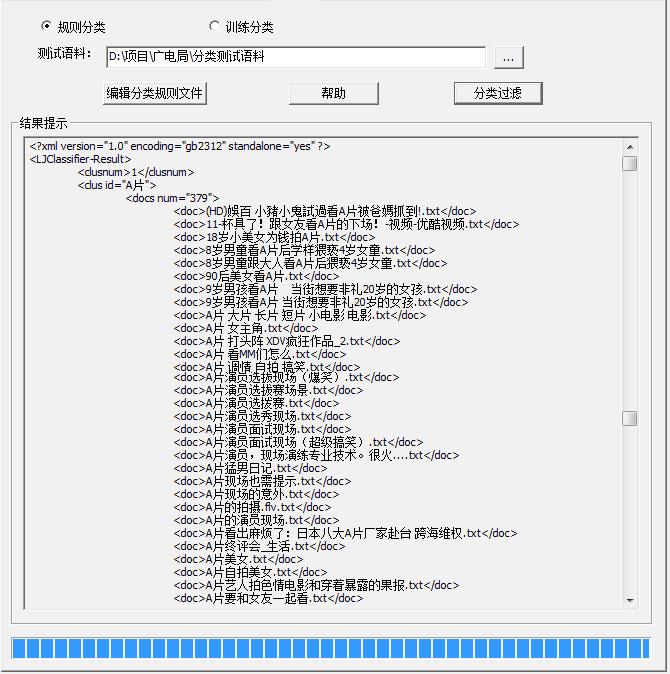
图2:灵玖IFCA系统处理后的结果
技术特点:
1.精准的切词:
使用先进的灵玖LJWS切词技术,准确高效的对句子切分,避免了歧义的产生;
2. 快速高效:
IFCA系统单线程每秒可处理10MB的文本数据。
3.准确率高:
根据100万条数据的实际测试,准确率高达99.97%。
4.支持微博客、短信等短文本内容过滤:
支持微博客、短信等内容短小而又不规范的内容过滤。
5.智能学习功能:
IFCA系统的所有的知识库是通过机器学习,自动抽取新的语言知识,以适应新的网络语言变化,做到因时而变
6.技术先进:
IFCA系统综合运用了自然语言理解技术、信息检索技术、模糊匹配与机器学习技术,技术含量高。
运行环境:
操作系统:Linux2.6及以上;Windows Server
硬件配置:1台服务器即可